

E-Commerce ist heute eine vollständig datengetriebene Welt. Gleichzeitig werden diese Daten immer schwerer zugänglich: Ad-Blocker, Browser-Restriktionen und Consent-Anforderungen zählen zu den größten Hürden. Server-Side Tracking räumt diese Hindernisse nicht vollständig aus dem Weg, verbessert aber die Datenbasis erheblich und macht Unternehmen zukunftsfähig – vorausgesetzt, es wird richtig eingesetzt und verstanden. Analytics-Experte Stefan Lerch erklärt, warum es gerade jetzt so wichtig ist, auf Server-Side Tracking zu setzen.
Weshalb Client-Side Tracking nicht mehr ausreicht
Über viele Jahre hinweg waren Conversion-Tracking und Webanalyse über den Client beziehungsweise den Browser der Standard – und auch heute verlassen sich noch zahlreiche Unternehmen ausschließlich darauf. Beim Client-Side Tracking werden Daten an Tools wie Facebook, Google Ads, Criteo geleitet. Hierfür wird in der Regel ein Tag Management-System wie der Google Tag Manager eingesetzt, über das die Marketingpixel für diese Tools auf der Seite ausgeliefert werden.
Gründe, weshalb Client-Side Tracking nach wie vor weit verbreitet ist, sind vor allem:
- Die schnelle und einfache Implementierung ohne Bedarf an spezialisierten IT-Ressourcen
- Geringe Kosten ohne laufende Infrastrukturaufwände
- Eine lange Historie mit breiter Tool-Unterstützung und aktiver Community
Der größte Showstopper des Client-Side Trackings ist, dass Tags nicht ausgespielt werden können bzw. deren Funktion eingeschränkt ist. Zu den Ursachen hierfür zählen unter anderem Browser-Restriktionen, Ad-Blocker oder abgelehnter Consent, die Folge sind erhebliche Einbußen bei der Datenqualität.
Darüber hinaus gibt es weitere Faktoren, die sich negativ auswirken:
- Das Laden zahlreicher Skripte verlängert die Seitenladezeit und verschlechtert das Nutzererlebnis
- Die Datenübertragung erfolgt häufig über Drittanbieter, was zusätzliche Datenschutzrisiken mit sich bringt
- Möglichkeiten zur Datenanreicherung sind begrenzt, ebenso die Kontrolle über automatisch erhobene Daten
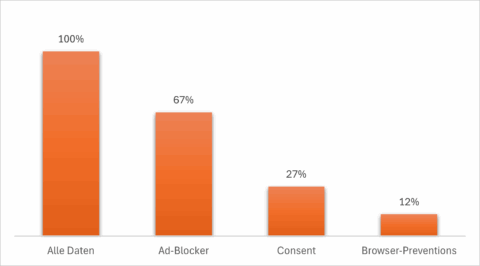
Berücksichtigt man alle Einflussfaktoren – und es existieren fundierte Studien zu deren Auswirkungen – bleiben, wie in Abbildung 1 dargestellt, am Ende nur noch rund 12 Prozent der Webseitenbesucher, deren Daten unverfälscht nutzbar sind. Damit wird sowohl die Analyse der Customer Journey als auch die gezielte Steuerung von Marketingmaßnahmen erheblich erschwert.
Was steckt hinter dem Buzzword „Cookieless Future“?
Häufig wird die sogenannte Cookieless Future als Hauptgrund für die Notwendigkeit von Server-Side Tracking genannt. Diese Darstellung ist jedoch nicht ganz korrekt.
Auch in Zukunft wird es Cookies geben – andernfalls wären grundlegende Funktionen wie Onlinekäufe nicht möglich. Das ist auch den Browser-Anbietern bewusst und funktional notwendige First-Party Cookies sind weiterhin erlaubt. Von einer vollständig cookielosen Zukunft kann also keine Rede sein. Allerdings versuchen Browser zunehmend zu bewerten, welche First-Party Cookies tatsächlich notwendig sind, und beschränken deren Laufzeit oder Nutzung. Dadurch wird Client-Side Tracking weniger granular.
Anders verhält es sich bei Third-Party Cookies. Sobald Cookies auch über andere Webseiten ausgelesen werden sollen, um Nutzerveralten erfassbar zu machen, blockieren Browser wie Safari, Firefox oder Edge das Setzen dieser Cookies. Umfassendes Tracking oder Retargeting ist damit kaum noch möglich. Zwar existieren erste Tests mit cookielosen Alternativen, doch Stand heute gilt: Eine verlässliche Marketingsteuerung lässt sich auf Basis von Third-Party Cookies nicht mehr aufbauen.
Was genau ist Server-Side Tracking?
Der zentrale Unterschied zum Client-Side Tracking besteht darin, dass im Browser des Nutzenden nur noch ein einziger Tag ausgeführt wird. Dieser Tag übermittelt die gesammelten Informationen an den eigenen Server des Unternehmens oder alternativ in eine Cloud. Erst dort werden die Daten in dem Client verarbeitet, auf einzelne Marketingtags verteilt und an Tools wie Google Analytics oder Google Ads weitergeleitet.
Da im Browser nur noch ein Tag geladen wird, bleibt die Seitenladezeit stabil. Gleichzeitig verbleiben Datenhoheit und Kontrolle vollständig beim Unternehmen. Die Kommunikation mit Drittanbietern wird jetzt vom Unternehmen individuell gesteuert, wodurch die Datensicherheit steigt und die Datenqualität deutlich verbessert wird. Zusätzlich können Daten im Server-Container vor der Weiterleitung um sensible Informationen wie Gewinnmargen angereichert werden, welche nicht im Browser für jeden sichtbar sein sollen.
Im Vergleich zum Client-Side Tracking ist Server-Side Tracking jedoch deutlich anspruchsvoller. Sowohl Einrichtung als auch Betrieb erfordern fundierte technische Kenntnisse. Zudem müssen Ressourcen eingeplant werden, um das Setup kontinuierlich zu überwachen und anzupassen. Hinzu kommen laufende Kosten für die technische Infrastruktur, die je nach Anbieter und Traffic variieren.
Was ist Server-Side Tracking nicht?
Server-Side Tracking wird häufig als Allheilmittel gegen Datenverluste durch Ad-Blocker, abgelehnten Consent oder Browser-Restriktionen betrachtet. Diese Erwartung ist jedoch unrealistisch. Auch mit Server-Side Tracking lassen sich nicht alle verlorenen Daten zurückgewinnen.
Bei Ad-Blockern hängt die Übertragung davon ab, welcher Tag-Manager eingesetzt wird und welcher Ad-Blocker aktiv ist. Aktuell ist davon auszugehen, dass insbesondere GA4-Pixel erkannt und blockiert werden, was weiterhin zu Datenverlusten führt. Google arbeitet jedoch bereits an Lösungen, um die Übermittlung an den Server-Container künftig zuverlässiger zu gestalten.
Unabhängig vom Tracking-Setup bleibt der Consent des Nutzenden für die Verarbeitung personenbezogener Daten zwingend erforderlich. Ohne Einwilligung dürfen solche Daten nicht erfasst werden. Theoretische Workarounds wie Anonymisierung oder Pseudonymisierung sind technisch sehr komplex, zeitaufwendig und bergen bei fehlerhafter Umsetzung erhebliche Risiken für die Datenqualität. Hier ist besondere Vorsicht geboten.
Ein wesentlicher Vorteil von Server-Side Tracking zeigt sich bei den Browser-Restriktionen. Mit dem Einsatz von Server-Side Tracking können die browserseitigen Einschränkungen von First-Party Cookies, wie beispielsweise dem von Facebook, umgangen werden. Zusätzlich ermöglicht das Server-Side-Tracking, auch Third-Party Cookies in einem First-Party Cooky-Kontext zu setzen und sie somit wieder für Marketing-Pixel zugänglich zu machen. Dadurch stehen deutlich mehr Daten zur Verfügung.
Zusammenfassend lässt sich sagen, dass Server-Side Tracking eine deutlich bessere Datenbasis für Analysen, Auswertung und Steuerung bietet als Client-Side Tracking. Von einer vollständigen Datenerfassung aller Nutzer sind wir dennoch weit entfernt.
Welche Plattform ist für Server-Side Tracking optimal?
Die Anbieter-Landschaft für Server-Side Tracking wächst und wird zunehmend unübersichtlich. Nachfolgend drei der bekanntesten Anbieter auf dem Markt im Kurzporträt:
- Google Server-Side Tagging (SGTM)
- Vorteile: SGTM ist weit verbreitet, gut dokumentiert und verfügt über eine große Community. Die Anbindung an Google-Dienste wie BigQuery, Google Ads oder Looker Studio ist über die Google Cloud problemlos möglich, etwa zur Datenanreicherung oder Kampagnensteuerung.
- Nachteile: SGTM basiert auf der Übermittlung des clientseitigen GA4-Pixels, wodurch weiterhin Datenverluste durch Ad-Blocker entstehen. Eine unabhängige Implementierung außerhalb der Google Cloud ist zwar möglich, aber sehr aufwändig.
- Stape
- Vorteile: Stape bietet Server-Side Tracking als Full-Service an und übernimmt Management und Monitoring. Vorgefertigte Templates erleichtern die Implementierung, auch Datenanreicherung ist gut möglich.
- Nachteile: Auch hier ist das clientseitige Marketingpixel zwingend erforderlich, wodurch Datenverluste nicht vollständig vermieden werden.
- Jentis
- Vorteile: Jentis hat eine eigene Architektur, die für die Datenübertragung an den Server kein GA4 Pixel benötigt. Die Übermittlung der Daten erfolgt direkt und die Daten können ohne Verlust von Jentis verarbeitet werden. Zudem ermöglicht Jentis über die Synthetischen User auch Tracking ohne Consent für eine große Auswahl an Tools, indem es die Daten verlässlich anonymisiert und weiterhin für die Marketing Tools nutzbar macht.
- Nachteile: Der initiale Integrationsaufwand ist hoch. Datenanreicherung ist möglich, jedoch komplexer, da individuelle Bridges benötigt werden.
Gibt es Alternative zu Server-Side Tracking?
Es existieren Webanalysetools ohne Server-Side Tracking, diese gehen jedoch mit deutlichen Einschränkungen einher. Anbieter wie eTracker oder Econda ermöglichen das anonyme Tracking der Nutzer für die Webanalyse und nutzen diese Daten auch für den Conversion Upload für Google Ads, Bing oder Meta, jedoch werden keine Interaktionen übertragen und Remarketing ist nur eingeschränkt möglich.
Fazit: An Server-Side Tracking führt kein Weg vorbei
Die Entwicklung neuer Tools und technischer Lösungen schreitet aktuell schnell voran. Unternehmen, die jetzt in Server-Side Tracking investieren, schaffen eine solide Grundlage, um von zukünftigen Innovationen zu profitieren – und erzielen bereits heute messbare Vorteile.
- Mehr Datensicherheit
Auch unter erschwerten Bedingungen durch Ad-Blocker, Consent-Limits und Browser-Restriktionen lassen sich signifikant mehr Daten erfassen - Optimierte Marketing-Insights
Remarketing, Attribution und Customer Journeys sind deutlich verlässlicher messbar als beim Client-Side Tracking. - Zukunftssicher und zunehmend verpflichtend
Viele Marketing-Tools werden Server-Side Tracking künftig voraussetzen, um valide Daten zu erhalten.
Kurzum: Server-Side Tracking ist die technische Basis für nachhaltiges Wachstum und es ist flexibel, um auf alle zukünftigen Anforderungen reagieren zu können.
Du möchtest wissen, wie auch du die Datenbasis für künftige Kampagnensteuerung schaffst und wie du von Server-Side Tracking profitierst? Wir unterstützen dich!




